title: 链接过程剖析 date: 2014-11-05 10:47:06 categories: 编译器
tags: [链接, 重定位]
我们将用下面的代码作为实例进行分析。
// main.c
void swap(int *a, int *b);
int main(void)
{
int a, b;
a = 42;
b = 24;
swap(&a, &b);
return 0;
}
// util.c
#include <stdio.h>
void print() {
printf("hello, world.");
}
void swap(int *a, int *b) {
int tmp;
tmp = *a;
*a = *b;
*b = tmp;
}
编译如下:
gcc -c main.c util.c
gcc main.c util.c
这样我们得到三个文件: main.o, util.o, a.out,
.o文件为可重定位文件(linkable file),a.out为最终的可执行文件(executable file)
我们的上游产品长什么样
到现在为止,在linker的角度看,有两个可供我们使用的材料:main.o和util.o,
linker将把这两个文件链接成一个可执行文件(a.out)。
我们称.o文件为模块,让我们来看看这两个模块长什么样子。
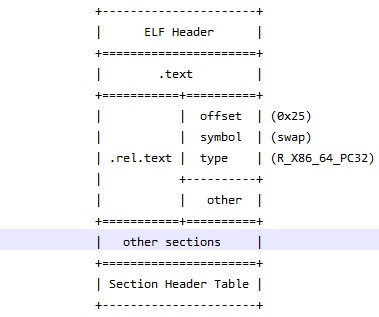

补充两个相关的数据结构定义:
typedef struct {
int name; // index in String table
int value; // offset in section or VM address
int size;
char type:4; // data, func, section, src file etc.
binding:4; // local or global
char reserved;
char section; // section number, e.g. 1(.text), 3(.data)
} Elf_Symbol;
说明:
value字段,如果重定位(见下)类型为相对地址引用,则value保存的是相对于其所在
section的偏移量,如果是绝对地址引用,它保存的是运行时虚拟内存地址。
typedef struct {
int offset; // 需要重定位的符号在section中的偏移,即重定位它
int symbol:24; // 符号名字在字符串表中的索引,即重定位到它
type:8; // 重定位类型,即如何重定位
} Elf32_Rel;
符号表表示“当前模块可对外提供哪些符号”,而重定位表表示“当前模块需要哪些符号”。
静态重定位
静态重定位有两部分组成:
- 重定位section并修改符号表和重定位表
- 重定位section中对symbol的引用
重定位section
linker把所有.o的.text合并为一个新的.text,把所有.symtab合并为一个
.symtab,把所有的.ref.text合并为一个.ref.text。然后为每个合并后的
section确定运行时地址,是的,运行时地址在链接阶段就一定确定了,0x8048000
和0x400000这样的虚拟地址就是在这个时候确定的。
合并.text section并设置运行时地址值,
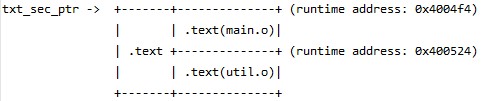
注意:
sizeof(.text of main.o) == 0x400524 - 0x4004f4 = 0x30;
这个值在修改符号表和重定位表的时候会用到。
合并.symtab section并修改symbol的offset值,

注意,0x30即为上面计算得出的0x30:
value of print = 0x30 = 0x00 + 0x30 = old value + 0x30;
合并.rel.text section并修改offset值,

注意: 因为main.o中的.text section在新的.text section中为第一个,
所以以前的偏移量仍然有效,故新、旧值相等。
重定位section中对symbol的引用
.symtab和.rel.text在合并时就一并修改了,但是.text却没有修改具体内容,
其内容中对symbol的引用还没有更新,这是因为对.text内容的修改需要用到.symtab
和.rel.text,现在它们都准备妥当了,是时候更新.text中对symbol的引用了。
- 需要更新哪些引用呢?
.text中都是二进制比特,如何区分哪些是需要更新的引用?.rel.text中记录的就是需要更新的引用。 - 这些引用需要更新为什么内容呢,即新的地址是什么?
.symtab中有记录。 - 如何更新呢,即更新算法是什么?
.rel.text中每个条目都记录了更新方法。
重定位类型,即rel.text中type定义的类型,有很多种,但是最常用的只有两种:
- 相对地址引用,R_386_PC32,R_X86_64_PC32,不同体系结构名称不同
- 绝对地址引用,R_386_32,R_X86_64_32,不同体系结构名称不同
相对地址引用是从当前正在执行的指令的PC值开始计数,当CPU碰到相对地址引用时,
会取出当前的PC值,然后跟引用值相加,这样就得到正确的地址了。比如
0x400500: call 0x7,CPU执行到这条指令的时候就会取出当前PC值(0x400500),
然后加上引用值(0x7),于是得到新的指令地址(0x400507),就会跳转到该值处
的函数继续执行。
绝对地址引用是从所在的section开始计数,即绝对地址引用就是节内偏移量。
重定位算法如下,
/*
RT_ADDR(x): 获取x的运行时地址
*/
foreach section s {
foreach relocation entry r {
/*
refptr: 合并后的section中,需要更新的引用的地址
s: 合并后section的地址,如txt_sec_ptr
r.offset: 需要更新的引用在section中的偏移量(合并section时已经更新过了)
*/
refptr = s + r.offset;
// 更新相对地址引用
if(r.type == R_386_PC32) {
// 运行时引用的地址 = 运行时section的地址 + 引用的偏移量
rt_refaddr = RT_ADDR(s) + r.offset;
/*
更新合并后的section中引用的值。
括号中的减法很显然,symbol的运行时地址减掉引用的运行时地址,
就得到了偏移量,这不就结束了吗,为何还要加上 *refptr 呢?
见后面的分析。
*/
*refptr = (RT_ADDR(r.symbol) - rt_refaddr) + *refptr;
}
// 更新绝对地址引用
if(r.type == R_386_32) {
// 为何还要加一个 *refptr(总是零?)
*refptr = RT_ADDR(r.symbol) + *refptr;
}
}
}
为何还要加上*refptr?
根本原因是PC总是指向当前指令的下一条指令。所以我们要想得到当前指令地址就要根据 下一条指令地址计算才行,但是当前指令是多大呢?这个在编译的时候会知道,另外不同 的指令编码方式(32bit? 64bit?)也会对这个偏移产生影响,所以在编译期就确定这个微调 的值,从而链接器就不用大费周章的去区分不同机器的指令编码方式了。
更新相对地址引用
- 取得需要更新的引用的链接时地址: txt_sec_ptr + 重定位表项中记录的offset
- 计算该引用的运行时地址: RT_ADDR(.text) + 重定位表项中记录的offset,section
的运行时地址是链接器固定死的,如
0x8048000、0x400000等。 - 计算所引用symbol的运行时地址: RT_ADDR(r.symbol)
- (3) - (2)记得到相对地址,然后赋值到(1)的地址处。
更新绝对地址引用
- 取得需要更新的引用的链接时地址: txt_sec_ptr + 重定位表项中记录的offset
- 取得symbol的地址,直接赋值到(1)的地址处即可。
(over)